
Why reliability, invariants, and guardrails matter more as AI accelerates code production.
Introduction
AI has already changed the rate at which software can be produced.
What remains unclear is how much faster software systems can safely change.
The ability to produce change is not the same as the ability to absorb its impact.
Systems, operational safeguards, and the humans responsible for them can only absorb so much change at a given moment. Beyond that point, the result is not acceleration but saturation: shallow reviews, operational stress, fragile releases, and systems that fail in ways no one fully understands.
Saturation can emerge from many sources: operational capacity, deployment throughput, incident response bandwidth, or simply the cognitive load placed on engineers and operators.
AI dramatically increases change production velocity.
But change impact velocity — the rate at which systems and organizations can safely absorb change — remains constrained.
Change Production vs Change Absorption
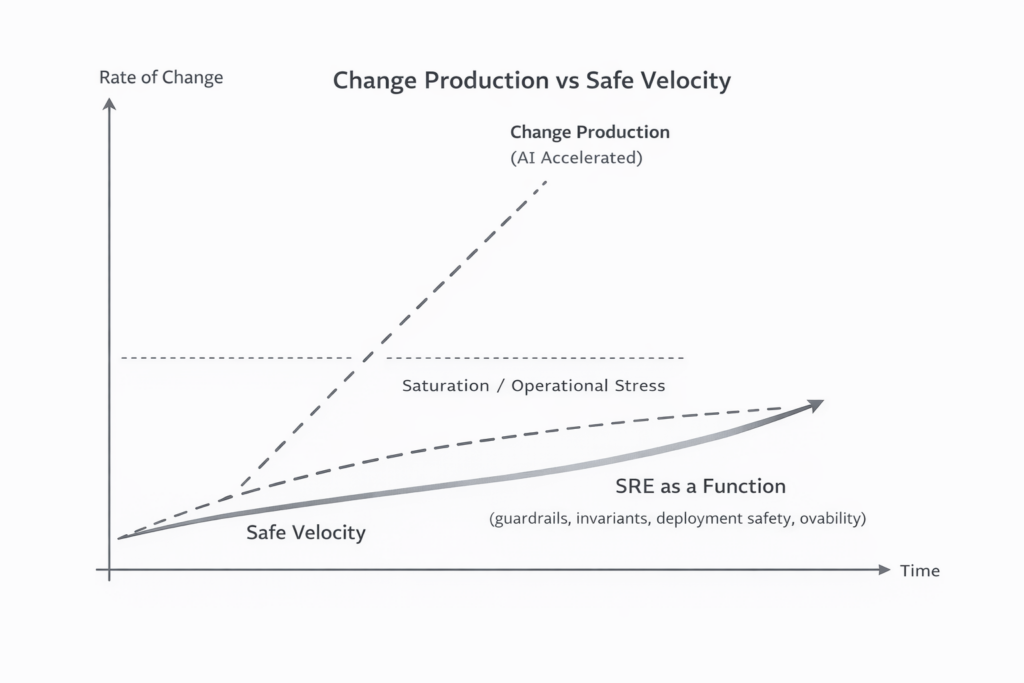
Figure:
AI dramatically increases the rate at which software changes can be produced. The ability of systems, teams, and users to safely absorb change grows more slowly. The widening gap creates operational pressure where reliability guardrails — invariants, deployment safety, and observability — become critical to sustaining safe velocity.
As these two forces diverge, constraints shift.
One of the first engineering practices likely to feel that pressure is traditional pull request review.
A Hypothesis Worth Testing
Consider the following hypothesis:
In environments where AI significantly increases the production velocity of software changes, shifting to AI-first pull request review that enforces explicit system invariants — while reserving human review for high-risk architectural or Tier-0 changes — will maintain or improve system reliability while reducing review latency.
This is not a prediction. It is a testable claim.
If AI-first review increases escaped defects or change failure rate, the hypothesis fails.
If reliability holds while review latency drops, it gains support.
The mechanism behind the hypothesis is more important than the claim itself.
AI Doesn’t Remove Constraints. It Moves Them.
For much of modern software development, a significant portion of engineering effort was spent writing and implementing code. While other constraints existed across the lifecycle, coding itself represented a large share of developer time.
What once resembled a pipeline like this:
Idea → Coding → Review → Deployment → Operations
↑
Largest share of engineering effort
begins to shift as AI accelerates implementation.
Coding becomes fast. Review, validation, and deployment safety become the new constraints.
Beyond the technical system itself, another limit appears: the ability of users, customers, and organizations to absorb change.
Systems can only evolve safely as fast as both their technical safeguards and the humans interacting with them can adapt.
This shift is already visible elsewhere in the software lifecycle.
Mirko Novakovic recently posed a similar question about incident response: would we trust AI agents to detect an incident, generate a fix, and deploy it autonomously?
Technically, this is already possible.
The concern, as incident.io CEO Stephen Whitworth pointed out, is not whether AI can generate a fix — it is whether that fix can be deployed safely. Without mechanisms that limit blast radius, such as progressive deployment or cell-based architectures, autonomous change becomes dangerous.
AI does not remove constraints.
It exposes them.
Why Traditional PR Review Doesn’t Scale
To understand why pull request review becomes strained under higher change velocity, it helps to examine what human review actually does today.
Human code review relies heavily on heuristics.
Reviewers examine a change and ask questions such as:
- Does this look correct?
- Does this follow conventions?
- Could this introduce risk?
In practice, pull request review tends to address three different concerns simultaneously:
basic correctness, architectural consistency, and operational safety.
The first two are increasingly amenable to automation or AI assistance.
Operational safety, however, depends on how a system behaves under load, failure conditions, and real-world traffic — something that cannot be fully evaluated from a code diff alone.
As the volume and frequency of changes increase, attention becomes the scarce resource. Reviews become faster and shallower. Large diffs are skimmed. Small changes accumulate quickly. Review latency increases while depth of reasoning decreases.
Human review remains valuable.
But human attention does not scale.
The Illusion of Safety in Human Review
Many organizations implicitly treat pull request review as a safety mechanism.
An experienced engineer looks at a change and determines whether it appears safe.
When this works, it works because the reviewer carries deep system knowledge.
But this also reveals a structural fragility.
If the safety of a system depends primarily on the attention and intuition of a small number of engineers during code review, then the system’s safety model relies on a scarce cognitive resource.
Human review is useful, but it is not a scalable safety mechanism.
In many organizations it compensates for structural safeguards that do not yet exist.
The deeper shift is from cognitive safety, where humans attempt to detect problems during review, to structural safety, where systems enforce constraints continuously.
The Safe Velocity Control Stack
Reliable systems rarely depend on a single safety mechanism.
Instead they rely on layers of safeguards operating at different stages of the system lifecycle — from design constraints, to change validation, to runtime awareness and organizational learning.
The Safe Velocity Control Stack is one way to visualize these layers.

Safe velocity emerges from the interaction of these layers.
If code review is the only place where system safety is validated, the system effectively has a single defensive layer.
That is a fragile position for any complex system.
AI Review as Constraint Enforcement
If human attention cannot scale indefinitely, the question becomes how systems can enforce safety constraints automatically.
Instead of asking whether a change looks correct, systems can validate whether it violates defined invariants such as:
- architectural boundaries
- dependency constraints
- retry and timeout policies
- security and data isolation rules
- SLO risk thresholds
Examples include:
- preventing direct database access from certain services
- enforcing exponential backoff in retry loops
- blocking synchronous dependencies between critical services
- requiring feature flags for certain classes of change
In principle, automated systems can evaluate these constraints across large codebases and dependency graphs.
The hypothesis explored here is that AI-assisted validation can perform this task consistently enough to improve review scalability without degrading reliability.
In many emerging development workflows, these checks may run as part of automated feedback loops between code generation systems and validation agents before a human reviewer becomes involved. These loops can simplify generated code, validate test data against service interfaces, or insert observability instrumentation.
Human judgment then focuses where it matters most: architectural intent, alignment between the problem being solved and the solution being implemented, system evolution, and the detection of unknown risks that automated checks cannot yet recognize.
Reliability Enables Safe Velocity
Reliability engineering is often framed as the discipline that prevents failure.
A more useful framing may be this: reliability enables safe velocity.
Large distributed systems behave less like static machines and more like dynamic systems. They accumulate pressure through queues, resource contention, and coupling between services.
Under those conditions the question is not only whether code is logically correct, but how the system behaves when a change interacts with load, latency, or failure conditions.
The sustainable velocity of a system is determined by:
- architectural boundaries
- deployment safety mechanisms
- observability
- operational response capacity
- human cognitive limits
AI increases the ability to generate change.
Reliability determines how quickly that change can be safely absorbed.
Sylvain Kalache (Rootly AI Labs) described this dynamic in his SREcon EMEA 2025 talk “From Vibes to Outages: Riding the AI Code Wave.”
He summarized incident pressure using a simple model:
Incident Rate ≈ λ + (c × p)
Where:
λ = baseline system failure rate
c = number of changes per unit time
p = probability that a change introduces failure
AI dramatically increases c, the rate at which changes can be produced. If p remains constant, incident rates rise.
Structural safeguards — invariants, deployment safety, observability, and blast radius control — are what reduce p, allowing systems to sustain higher rates of change without increasing incident frequency.
A Practical Experiment
This hypothesis can be tested without redesigning an entire engineering organization.
Start with a bounded experiment.
Step 1 — Define Your Constraints
Ask:
- Are architectural boundaries clearly defined?
- Do services have explicit SLOs?
- Are systems classified by risk tier?
- Are policies encoded as code or automation?
- Are dependency and retry rules documented?
- Can blast radius expansion be detected?
Organizational Scale
The rigor required for defining constraints will vary depending on the stage of an organization.
A five-person startup does not need the same level of formalization as a large enterprise platform team.
Early-stage teams may rely on shared conventions and lightweight safeguards.
As systems grow, those constraints typically become more explicit and automated.
Step 2 — Select a Non-Critical Domain
Choose a system with:
- clear ownership
- moderate production traffic
- stable CI/CD pipelines
- no Tier-0 risk profile
Step 3 — Introduce AI-First Review
Pull requests are first validated against automated invariants.
Human review occurs when:
- architectural boundaries are crossed
- new dependencies are introduced
- SLO risk is detected
- automated systems flag uncertainty
Guardrail systems will occasionally block changes that are ultimately safe. These cases should not be treated as failures but as signals that constraints may need refinement.
Track:
- review latency
- change failure rate
- escaped defect rate
- incident severity
- developer cognitive load
- cost per review
In high change-velocity environments, acceptable change failure rates may need to be significantly lower than traditional benchmarks in order to maintain stable SLO performance.
Step 4 — Evaluate
Several outcomes are possible depending on the trade-offs between reliability and review latency.
- Reliability improves while latency improves → strong evidence supporting the hypothesis.
- Reliability remains stable while latency improves → still a meaningful gain.
- Reliability degrades → the hypothesis fails.
Each outcome reveals where the real constraints in the system lie.
The Real Question
The debate about AI reviewing code often misses the deeper issue.
The question is not whether AI can review pull requests.
The real question is whether our systems are defined clearly enough that any mechanism — human or machine — can determine whether a change violates critical constraints.
If the safety of a system depends primarily on human attention during code review, the system was never truly safe to begin with.
AI does not create that fragility.
It simply exposes it.
Acknowledgements
I’m grateful to several colleagues and members of the SRE community who reviewed early drafts of this article and helped sharpen the ideas presented here, including:
- Reilly Herrewig
- Andrew Mallaband
- Sylvain Kalache
- Jerry Drum
- Eden Trainor
- Amin Astaneh
- Kyle Forster
- Roxane Fischer
Any remaining mistakes or oversights are my own.